[운영체제](반효경) 11강. File System
File And File System
- File
- “A named Collection of related information”
- 일반적으로 비휘발성의 보조기억장치에 저장
- 운영체제는 다양한 저장장치를 file이라는 동일한 논리적 단위로 볼 수 있게 해줌
- Operation
- create, read, write, reposition(lseek) - 파일의 포인터를 이동, delete, open, close 등
- File attribute(혹은 파일의 metadata라고도 일컬음)
- 파일 자체의 내용이 아니라 파일을 관리하기 위한 각종 정보들
- 파일 이름, 유형, 저장된 위치, 파일 사이즈
- 접근 권한(읽기/쓰기/실행), 시간(생성/변경/사용), 소유자 등
- 파일 자체의 내용이 아니라 파일을 관리하기 위한 각종 정보들
- File System
- 운영체제에서 파일을 관리하는 부분
- 파일 및 파일의 메타데이터, 디렉토리 정보 등을 관리
- 파일의 저장방법 결정
- 파일 보호 등
Directory and Logical Disk
- Directory
- 파일의 메타데이터 중 일부를 보관하고 있는 일종의 특별한 파일
- 그 디렉토리에 속한 파일 이름 및 파일 attribute 들
- Operation
- search for a file, create a file, delete a file
- list a directory(리스트를 보는 것), rename a file, traverse the file system(파일시스템 전체를 탐색)
- Partition(= Logical disk)
- 하나의 디스크 안에 여러 파티션을 두는게 일반적
- 여러 개의 물리적인 디스크를 하나의 파티션으로 구성하기도 함
- 디스크를 파티션으로 구성한 뒤 각각의 파티션에 file s ystem을 깔거나 swapping 등 다른 용도로 사용할 수 있음
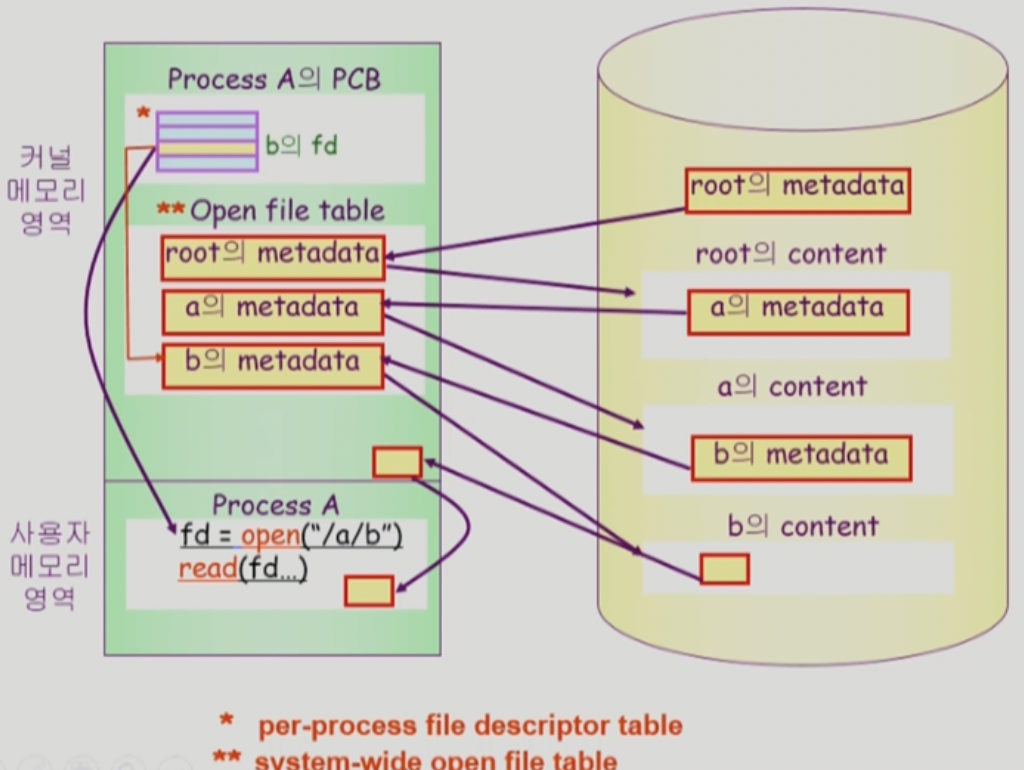
Open()
파일의 메타데이터를 메모리로 올리는 것 (system call의 일종)

e.g) open(”/a/b”)를 실행하면 일어나는 일
- 디스크로부터 파일 c의 메타데이터를 메모리로 가지고 옴
- 이를 위하여 directory path를 search
- 루트 디렉토리 /를 open하고 그 안에서 파일 a의 위치를 획득
- 파일 “a”를 open 한 후 read 하여 그 안에서 파일 b의 위치 획득
- 파일 “b”를 open 한다.
- Directory Path 의 search에 너무 많은 시간이 소요되기 때문에 Open을 read/write와 별도로 둔다.
- 한번 open한 파일은 read/write 시 directory search 불필요
- Open file table
- 현재 open 된 파일들의 메타데이터 보관소(in memory)
- 디스크의 메타데이터보다 몇가지 정보가 추가
- Open한 프로세스의 수
- File offset: 프로세스가 파일 어느위치에 접근 중인지 표시(별도 테이블 필요)
- File descriptor(file handle, file control block)
- Open file table에 대한 위치 정보(프로세스 별)
File Protection
- 각 파일에 대해 누구에게 어떤 유형의 접근(read/write/execution)을 허락할 것인가?
- Access Control 방법
- Access Control Matrix(행렬)
- Access Control list: 파일별로 누구에게 어떤 접근 권한이 있는지 표시(Linked List로)
- Capability: 사용자 별로 자신의 접근 권한을 가진 파일 및 해당 권한 표시
- Grouping(일반적인 운영체제에서 사용하는 방법)
- 전체 user를 owner, group, public의 세 그룹으로 구분
- 각 파일에 대해 세 그룹의 접근 권한(rwx)를 3비트 씩으로 표시(9개의 비트로) - e.g)UNIX
- Password
- 파일마다 패스워드를 두는방법(디렉토리 파일에 두는 방법도 가능)
- 모든 접근 권한에 대해 하나의 password: all-or-nothing
- 접근 권한 별 패스워드 → 암기 문제와 관리 문제가 있음
- Access Control Matrix(행렬)
File System의 Mounting

- 다른 파일시스템의 루트디렉토리로 접근할 수 있게 해줌
Access Method 접근 방법
시스템이 제공하는 파일 정보의 접근 방식
- 순차 접근(sequential access)
- 카세트 테이프를 사용하는 방식처럼 접근
- 읽거나 쓰면 offset은 자동적으로 증가
- 직접 접근(direct access, random access)
- LP 레코드 판과 같이 접근하도록 함
- 파일을 구성하는 레코드를 임의의 순서로 접근할 수 있음
Allocation of File Data in Disk
임의의 크기의 파일을 블럭단위로 저장하고 있음
Contiguous Allocation
하나의 파일이 디스크에 연속해서 저장되는 방법

- 장점
- Fast I/O(공간 효율성 보다는 속도 효율성이 중요한 경우!!)
- 한번의 seek/rotation으로 많은 바이트 transfer
- realtime file용으로, 또는 이미 run 중이던 process의 swapping 용도로 사용
- Direct access(=random access) 가능
- Fast I/O(공간 효율성 보다는 속도 효율성이 중요한 경우!!)
- 단점
- 외부조각이 생길 수 있다.
- 파일 grow가 어려움
- 파일 생성 시 얼마나 큰 hole을 배정할 것인가?
- grow 가능 vs 낭비(internal fragmentation) → trade off
Linked Allocation

- 장점
- 외부조각 발생 안함
- 단점
- No random access(순차적 접근해야해서 시간이 많이 듬)
- Reliability 문제
- 한 섹터가 고장나 pointer가 유실되면 많은 부분을 잃음
- Pointer를 위한 공간이 block의 일부가 되어 공간 효율성을 떨어뜨림 - 작은 문제긴 하다
- 512 bytes/sector, 4bytes/pointer
- 변형
- FAT(File-Allocation Table) 파일 시스템
- 포인터를 별도의 위치에 보관하여 reliability와 공간 효율성 문제 해결
- FAT(File-Allocation Table) 파일 시스템
Indexed Allocation
인덱스 블록 내부에 파일이 저장되어있는 블록들의 위치를 저장해놓는 방법

- 장점
- External fragmentation이 발생하지 않음
- Direct access 가능
- 단점
- Small file의 경우 공간 낭비(실제로 많은 file들이 small) → 블럭이 2개 필요하기 때문에!
- Too Large file의 경우 하나의 block로 index를 저장하기에 부족
- 해결방안
- Linked scheme
- multi-level index
- 해결방안
위의 방법들은 이론적인방법, 아래부터는 실제로 사용되는 파일시스템에 대해서 다룬다.
UNIX 파일 시스템

- Boot block
- 어떤 파일 시스템이던 공통적으로 갖고 있는 구조
- 부팅에 필요한 정보를 가지고 있다.(bootstrap loader)
- Super blcok
- 파일 시스템에 관한 총체적인 정보를 갖고 있다.(어디가 빈 블록이고 어디가 사용되는 블럭인지? 어디까지가 Inode 블록인지? 등)
- Inode List
- 파일 이름을 제외한 파일의 모든 메타데이터를 저장 → 파일 이름은 디렉터리가 갖고 있음
- 파일 하나당 할당이 됨
- 큰 파일의 경우 indirect를 사용하여 데이터 블럭 위치를 갖고 있음(그림 참조)
- Data block
- 실제 데이터를 갖고 있는 부분
FAT 파일 시스템

- Linked Allocation 사용
- FAT 배열을 확인해서 다음 위치를 알 수 있다.
- 직접 접근도 가능하다
Free - Space Management
빈 공간을 관리하는 방법
1. Bit map or Bit Vector

- 특성
- 부가적인 공간을 필요로 함
- 연속적인 n개의 free block를 찾는데 효과적이다
2. Linked List
- 모든 free block들을 링크로 연결(free link)
- 연속적인 가용공간을 찾는 것은 쉽지 않다
- 공간의 낭비가 없다
3. Grouping
- Linked List 방법의 변형
- 첫번째 free block이 n개의 pointer를 가짐
- n-1 pointer는 free data block를 가리킴
- 마지막 pointer가 가리키는 block는 또 다시 n pointer를 가짐
4. Counting
- 프로그램들이 종종 여러개의 연속적인 block를 할당하고 반납한다는 성질에 착안
- first free block, # of contiguous free blocks를 유지 - 어디가 비어있는지, 몇개가 연속적으로 비어있는지에 대한 정보
Directory Implementation
- Linear List
- File name, file의 메타데이터의 list
- 구현이 간단
- 디렉토리 내에 파일이 있는지 찾기 위해서 선형 탐색이 필요(time - consuming)
- Hash Table
- linear list + hashing
- Hash table은 file name을 이 파일의 linear list의 위치로 바꾸어줌
- search time을 없앰
- Collision 발생 가능
- File의 메타데이터 보관 위치
- 디렉토리 내에 직접 보관하는 경우
- 디렉토리에는 포인터를 두고 다른곳에 보관
- inode(UNIX), FAT 등
- Long file name의 지원
- <file name, file의 metadata>의 list에서 각 엔트리는 일반적으로 고정 크기
- file name이 고정 크기의 entry 길이보다 길어지는 경우 entry의 마지막 부분에 이름의 뒷부분이 위치한 곳의 포인터를 두는 방법
- 이름의 나머지 부분은 동일한 directory file의 일부에 존재
VFS and NFS
- Virtual File System(VFS)
- 서로 다른 다양한 file system에 대해 동일한 시스템 콜 인터페이스(API)를 통해 접근할 수 있게 해주는 OS의 layer
- Network File System(NFS)
- 분산 시스템에서는 네트워크를 통해 파일이 공유 될 수 있음
- NFS는 분산 환경에서의 대표적인 파일 공유 방법임

Page Cache and Buffer Cache
- Page Cache
- 가상메모리의 페이징 시스템에서 사용하는 페이지 프레임을 캐싱의 관점에서 설명하는 용어
- Memory-Mapped I/O를 쓰는 경우 file의 I/O에서도 page cache 사용
- Memory-Mapped I/O
- File의 일부를 virtual memory에 mapping 시킴
- 매핑시킨 영역에 대한 메모리 접근 연산은 파일의 입출력을 수행하게 함
- read() system call과 비교
- read: 카피해서 해당 프로세스의 메모리 공간에 제공하게 됨
- m-Mapped I/O: 메모리에 접근하면 그 파일에 접근하게 됨 - 더 빠르다 / copy overhead가 없고 운영체제의 도움을 받을 필요가 없음 / 단, 공유 자원의 문제가 있을 수도 있음 - read /write 콜의 경우 copy해서 전달하기 떄문에 그런 문제가 없음
- Buffer Cache
- 파일시스템을 통한 I/O 연산은 메모리의 특정 영역인 buffer cache 사용
- 파일 사용의 Locaility 활용
- 한번 읽어온 block에 대한 후속 요청 시 buffer cache에서 즉시 전달
- 모든 프로세스가 공용으로 사용
- Replacement algorithm 필요(LRU, LFU 등)
- Unified Buffer Cache
- 최근의 OS에서는 기존의 buffer cache가 page cache에 통합됨(e.g Linux)
- 왼쪽의 경우 read, write system call이 있을때는 그 내용이 buffer cache에 있든 없든 운영체제에 요청을 해서 받아와야 하고, M-Mapped를 쓰게되면 운영체제를 부르지 않고(커널의 도움을 받지 않고) 프로세스가 자신의 메모리에 접근하면서 I/O를 하게됨
- 우측의 경우도 read, write 시 운영체제에 CPU 넘어감 → 캐시에 있는 내용이면 그냥 카피해 주면되고 아니라면 디스크의 파일시스템에서 읽어서 전달. M-Mapped의 경우는 사용자 프로그램의 주소영역에 페이지 캐시가 매핑되어 프로세스가 직접 읽고 쓰고 할 수 있다.
- code 부분은 swap영역으로 가는게 아니고 파일시스템의 실행파일에 파일의 형태로 존재함(memory-mapped I/O - Loader)
- 데이터 파일의 경우 swap으로 가는게 아니고, 수정된 내용을 반영해서 파일시스템에다가 써줘야 함
- 다른 프로세스가 해당 파일을 가져와도 동일한 물리 메모리 영역에서 공유한다


'CS > OS' 카테고리의 다른 글
| [운영체제](반효경) 11강. Disk Management And Scheduling (0) | 2022.10.14 |
|---|---|
| [운영체제](반효경) 10강. Virtual Memory (0) | 2022.10.14 |
| [운영체제](반효경) 9강. Memory Management (0) | 2022.10.13 |
| [운영체제](반효경) 8강. Deadlock (0) | 2022.08.09 |
| [운영체제](반효경) 7강. Process Synchronization (0) | 2022.08.09 |